
Vamos configurar o ambiente para poder começar esse workshop e colocar o seu modelo de Machine Learning em produção!
Bem-vindes ao Workshop Machine Learning: da criação ao deploy de modelos de aprendizado de máquina, com a Jéssica Santos (head de dados na Neuralmed) e a Vivian Yamassaki (cientista de dados na Creditas)!
Neste workshop, vamos aprender desde a criação até como podemos disponibilizar os modelos de machine learning que desenvolvemos para que possam ser consultados para novos exemplos. Para isso, vamos trabalhar com dados da famosa competição do Titanic, presente no Kaggle 🚢.
Além de fazer e explicar sobre a etapa de deploy do modelo em si (ou seja, disponibilizar o modelo para ser consultado), também vamos passar pelas etapas de obtenção dos dados, feature engineering (que seria a etapa de pré-processamento dos dados, na qual fazemos as transformações necessárias para que eles sejam fornecidos para o modelo), modelagem e avaliação do modelo treinado. Dessas últimas etapas mencionadas, vamos focar especialmente na etapa de feature engineering, para que as transformações dos dados feitas durante o desenvolvimento do modelo também possam ser feitas do mesmo jeito quando colocamos o modelo em produção.
Já com relação à etapa de deploy, vamos criar uma API para que possamos chamar nosso modelo treinado e fornecer novos exemplos nunca antes vistos por ele para que ele possa gerar as predições que queremos.
Com os conhecimentos adquiridos deste workshop, que está separado em duas partes, você conseguirá construir um pré-processamento de dados estruturado que irá servir tanto para treinar o seu modelo quanto para fazer o deploy do mesmo – além de, é claro, conseguir fazer o deploy de outros modelos de machine learning que você treinar! ❤️ Preparades?
Dando start
Antes de mais nada, vamos primeiro configurar o ambiente para que você consiga acompanhar o workshop e codar junto com a gente!
 Se você é iniciante no mundo de aprendizado de máquina e Python, recomendamos que você faça primeiro o workshop Primeiros passos com Machine Learning: transformando dados em conhecimento! com Fernanda Wanderley (cientista de dados na Neuralmed), para aprender sobre as etapas comumente existentes em um fluxo de desenvolvimento de um modelo de machine learning.
Se você é iniciante no mundo de aprendizado de máquina e Python, recomendamos que você faça primeiro o workshop Primeiros passos com Machine Learning: transformando dados em conhecimento! com Fernanda Wanderley (cientista de dados na Neuralmed), para aprender sobre as etapas comumente existentes em um fluxo de desenvolvimento de um modelo de machine learning.
Algumas etapas abordadas no workshop Primeiros Passos, como a análise exploratória, foram puladas por questões de tempo, assim como alguns conceitos que já haviam sido explicados anteriormente nele. Então, fica essa dica caso você precise obter esses conhecimentos iniciais antes de se aprofundar na parte do deploy. 😉
Para preparar seu ambiente de cientista de dados, vamos realizar as seguintes etapas:
- Instalar Python
- Preparar um ambiente virtual
- Instalar Bibliotecas
- Instalar PyCharm
- Separar recursos necessários
1. Escolha sua linguagem de programação: Instalando Python
Neste workshop, vamos utilizar o Python na versão 3.9.9. Caso você ainda não a tenha instalado no seu computador, faça essa instalação (aqui tem um guia com o passo a passo de como fazer).
2. Preparando um ambiente virtual: Configuração do virtualenv
Se instalarmos as ferramentas e bibliotecas diretamente na sua máquina, pode haver interferência nas ferramentas previamente instaladas no seu sistema operacional, como versão do Python, bibliotecas etc. Para evitar esse problema, uma boa prática quando estamos começando um novo projeto é configurar um ambiente virtual. Ele cria uma instância separada na qual você também controla a configuração de versões de ferramentas necessárias para esse workshop sem interferir no restante! Com o ambiente virtual, você garante um ambiente isolado para explorações! 🙂
Siga o passo a passo abaixo para configurar o seu de acordo com seu sistema operacional:
Windows
1. No terminal do Windows (iniciar > digite: cmd) https://www.programaria.org/o-que-e-o-terminal-ou-venha-conhecer-tela-preta/ digite o comando:
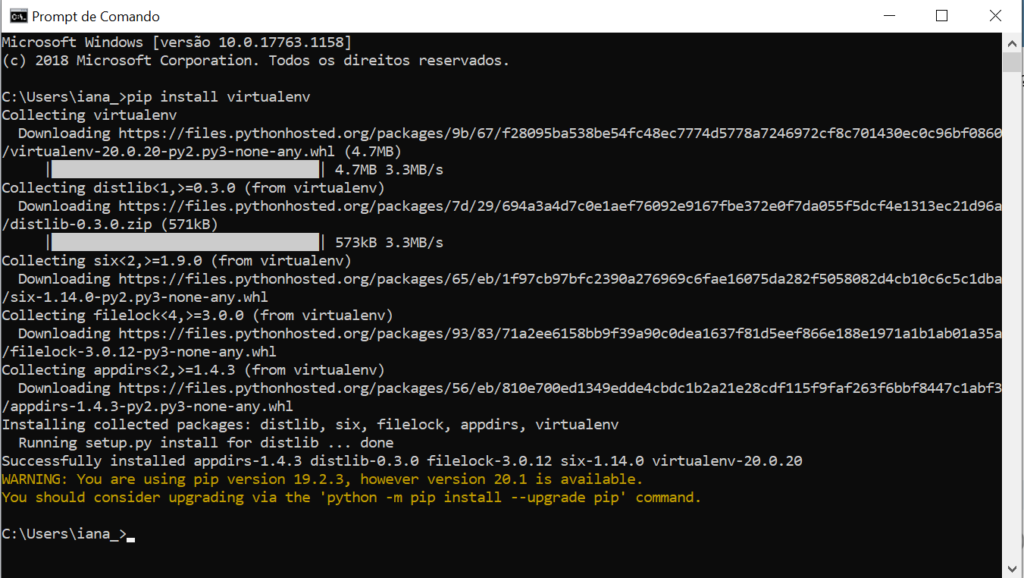
2. Criar o ambiente virtual na pasta chamada programaria com o comando
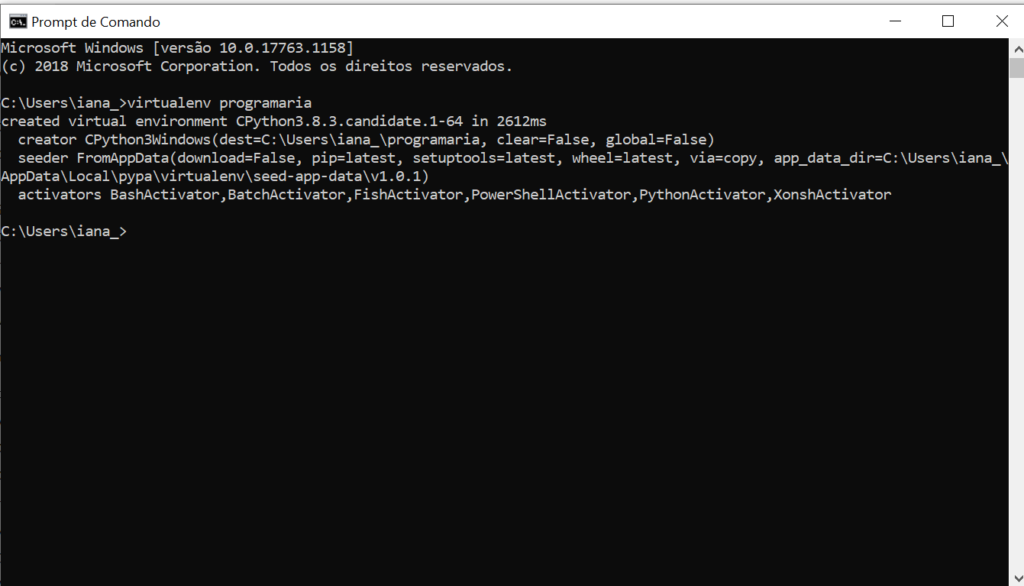
3. Ativar o recém-criado ambiente virtual chamado programaria com o comando
Observe que você deve usar o caminho completo de onde está a sua pasta programaria para que o computador consiga localizar corretamente o arquivo necessário (você pode procurar pela interface do gerenciador de arquivos e pastas para encontrar onde criou a pasta programaria)
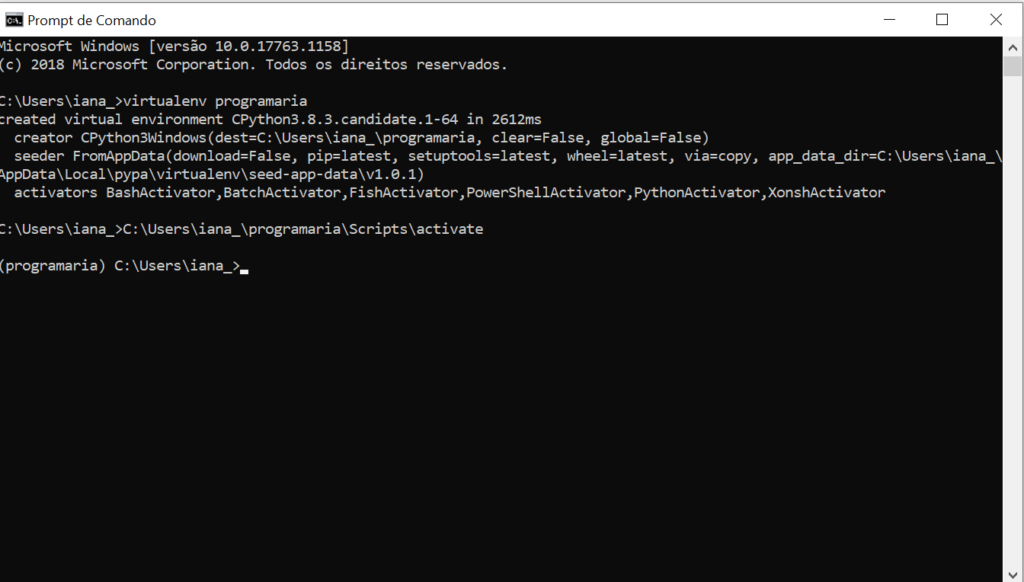
O ambiente estará funcionando quando, antes do nome do seu usuário e máquina, aparecer o nome atribuído a ele entre parênteses. No nosso caso, (programaria), como aparece na imagem.
Linux/Mac
Com o Python3.9 já instalado é hora de instalar o virtualenv
Depois de instalado, criaremos um ambiente virtual durante o nosso workshop, chamado de “programaria”, e o ativaremos. Siga as duas linhas códigos da imagem para criar o ambiente:
![]()
O ambiente estará funcionando quando, antes do nome do seu usuário e máquina,aparecer o nome atribuído a ele entre parênteses. No nosso caso, (programaria), como aparece na terceira linha da imagem.
Para desativar o ambiente é só usar o comando
Depois do workshop. você pode desinstalar deletando a pasta que criou para o virtualenv – no caso, a pasta “programaria” (dá para fazer pelo gerenciador de arquivo mesmo).
3. Escolha suas ferramentas: Instalando bibliotecas
Neste workshop, todas as bibliotecas necessárias estão no arquivo requirements.txt na raiz do repositório do Github. Para facilitar, você pode só abrir o requirements.txt no próprio Github e copiar o conteúdo para um arquivo no seu projeto com o mesmo nome. Estando com o ambiente ativado e na pasta em que o arquivo requirements.txt se encontra, basta rodar o comando:
> se der algum erro tente executar com pip3 no lugar do pip.
4. Escolha sua interface: Instalando o PyCharm
Esta etapa é totalmente opcional, tá bem? Você pode utilizar outra interface de sua preferência ou até mesmo um editor de texto. Só tome cuidado no caso de editores de texto mais simples que não te avisam sobre potenciais erros no seu código. Nesse caso, preste mais atenção ao que você está programando para não ficar batendo a cabeça por conta de um erro.
Agora que já instalamos o Python e configuramos o ambiente, chegou a hora de preparar a interface que vamos utilizar para programar. Neste workshop, será o PyCharm. Você pode fazer o download dele aqui. Siga a instalação de acordo com o seu sistema operacional.
Depois de instalar o PyCharm, vamos criar nossa pasta de trabalho. Crie uma nova pasta no seu computador e a chame de workshop. Essa pasta será sua pasta de trabalho, em que você salvará os arquivos e códigos que desenvolver durante o workshop.
Por fim, abra o PyCharm e vá em File > Open. Selecione a pasta workshop que você acabou de criar e dê um OK. Pronto, agora seu PyCharm está configurado para que você possa criar e trabalhar nos arquivos desse workshop de uma forma organizada, além de te ajudar a identificar potenciais erros no seu código!
Prontinho! Agora seu ambiente de cientista de dados está configurado! 😊
5. Separe recursos necessários: conjunto de dados e coragem
Já estamos quase acabando de preparar tudo o que precisamos para o workshop, mas está faltando algo muito importante: nossos dados.
- Conjunto de dados
Como falamos no começo do artigo, neste workshop vamos utilizar os dados do desafio do Titanic, que tem como objetivo predizer a chance de um passageiro ter sobrevivido ao naufrágio do Titanic.
Para poder fazer o download do conjunto de dados, primeiramente é preciso se registrar na plataforma do Kaggle. Após isso, basta acessar o link da competição que deixamos acima, clicar no botão “Join Competition” para poder participar da competição, clicar na aba Data e depois clicar no botão Download All no final dessa aba:
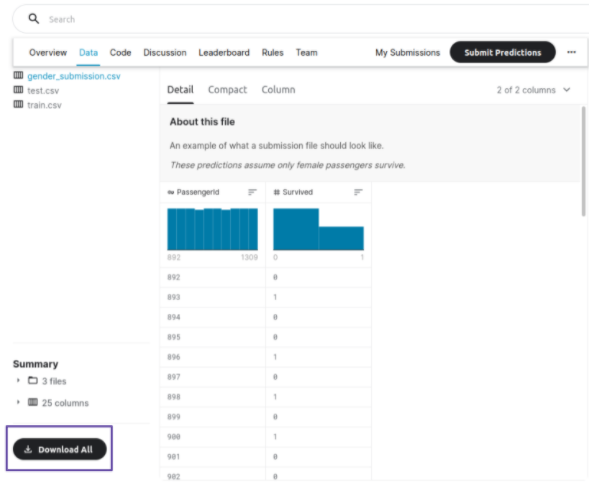
Descompacte o arquivo titanic.zip que você acabou de baixar. Dentro da nossa pasta de trabalho workshop, crie uma pasta chamada data e coloque os arquivos de treino e teste (train.csv e test.csv, respectivamente), que estavam nesse arquivo zipado, dentro dela:
UHUL! Agora que já temos nosso ambiente configurado, interface e nossos dados, já podemos colocar a mão na massa e iniciar o workshop!
Outras dicas de preparo importantes: proatividade, colaboração e energia!
Uma das principais características de uma pessoa que trabalha com tecnologia é aprender a aprender e isso está MUITO baseado em proatividade! Ficou com uma dúvida ou algo deu errado? Reflita sobre o que está acontecendo, tente entender qual erro está dando e busque no Google possíveis soluções – às vezes, só de jogar a mensagem de erro você já encontra uma resposta.
A outra habilidade é a colaboração: converse com pessoas que estão no mesmo desafio, ajude quem puder, faça perguntas e evolua seu raciocínio! Isso é fundamental para seu aprendizado!
Por fim, energia é sempre bom, né? Então, se espreguice, descanse os olhos e respire fundo!
Agora sim, você já está com tudo para assistir ao workshop!
Tire uma selfie pra registrar esse momento, poste nos stories com a hashtag #PrograMariaSprint, marque @programaria e bora! 😉
Agora que seu modelo está pronto, você pode ir para a parte 2 deste Workshop para aprender como colocá-lo em produção: Workshop MLOps: Aprenda a fazer deploy de modelos de Machine Learning
Caso queira consultar, aqui está também o Repositório no Github com o código que desenvolvemos durante o workshop.
Autoras Jéssica dos Santos de Oliveira é head de dados na NeuralMed, onde atua utilizando deep learning para auxiliar no diagnóstico e melhorar os sistemas de saúde em geral. Já trabalhou como cientista de dados em empresas do mercado financeiro e tem mestrado em Sistema de Informação, com linha de pesquisa em Inteligência de Sistemas. Seu projeto foi usar modelos de atenção visual baseados em reconhecimento de padrões para identificar autismo. Também participa de projetos que incentivam mulheres na área, sendo embaixadora do Women in Data Science (WiDS) São Paulo desde 2019, e cofundadora do Mulheres em IA (MIA), comunidade criada em 2020 durante a pandemia para abraçar e incentivar as mulheres que trabalham com dados. Vivian Yamassaki é cientista de dados na Creditas e mestra com pesquisa em Inteligência Artificial e área de aplicação em Bioinformática pela Universidade de São Paulo (USP). Curte se envolver em projetos que visam incentivar mulheres na área de ciência de dados, como a Mulheres em Inteligência Artificial (MIA) – criada em 2020 e da qual é uma das co-organizadoras – e o Women in Data Science (WiDS), do qual foi co-embaixadora em São Paulo entre 2019 e 2021. Mulheres em IA (MIA)
A comunidade Mulheres em IA (MIA) nasceu da união das embaixadoras do WiDS-SP e WiDS-RJ com o objetivo fortalecer ainda mais as mulheres brasileiras na área de Inteligência Artificial e dados no geral. Acesse o linktree e confira nossas redes sociais: https://linktr.ee/mulheres.em.ia Revisora Stephanie Kim Abe é jornalista, formada pela Escola de Comunicações e Artes da Universidade de São Paulo (ECA-USP). Trabalha na área de Educação e no terceiro setor. Esteve nos primórdios da Programaria, mas testou as águas da programação e achou que não era a sua praia. Mas isso foi antes do curso Eu Programo…
Este conteúdo faz parte da PrograMaria Sprint Área de dados.
O que você achou deste conteúdo? Responda nosso feedback:
excelente guia de instalação, eu gostei muito
Muito bom
Muito conteúdo novo, aprendi muita coisa. Senti algumas dificuldades como instalar o docker e o make, foram os momentos que tive maior dificuldade.