



Aprendizado de máquina ou Machine Learning é um dos ramos da Inteligência Artificial mais comentados atualmente, e grande parte das empresas desejam profissionais com experiência na área. Mas… o que de fato significa ‘Aprendizado de Máquina’? Como uma máquina pode aprender? Onde eu aplico isso?
Oi, gente! eu sou a Laura Damaceno, cofundadora da comunidade AI Girls e organizadora da comunidade DevAIWoman. Criei este guia à convite da PrograMaria para dar um direcionamento para quem quer começar na área!
‘Se preparem, Machine Learning está chegando’
O Machine Learning ou aprendizado de máquina está presente em quase toda a nossa vida: sabe aquela recomendação de amizades que temos no Facebook? Machine Learning. Recomendação de livros quando abrimos o site da Amazon? Machine Learning! Indicações do que ver da Netflix pro fim de semana? Machine Learning!
Tem uma frase que ouvi na estréia da revista do MIT no Brasil que foi marcante para mim, “A Inteligência Artificial vai se tornar lágrimas na chuva”. Ou seja, ninguém vai perceber, mas a IA estará em todos os lugares, e grande parte das pessoas nem reparam nisso.

“Machine Learning, Machine Learning em toda parte”
Conceitos Prévios
Para ninguém ficar confusa/o, vou explicar algumas definições básicas importantes antes de falar sobre aprendizado de máquina.
- Algoritmo/Método de Machine Learning: São as sequências de passos desenvolvidas geralmente por pesquisadores e pesquisadoras acadêmicas que utilizem abordagens matemáticas para executar a tarefa para resolver problemas. As bibliotecas já trazem esses algoritmos implementados, isso é, disponíveis para serem utilizados. Ex.: Algoritmo de regressão linear, regressão logística, k-means etc.
- Modelo: É o resultado do trabalho de profissionais que são cientistas de dados, que selecionam o melhor algoritmo para resolver seu problema, treinam e ajustam a partir do conjunto de dados específicos até que ele apresente um bom resultado. Ex.: O modelo em que a Juliana Cesaro trabalhou testando algoritmos de Regressão Linear, Random Forest e Gradient Boosting – optando pelo Gradient Boosting, da categoria Essemble para prever a relação entre preço e vendas do Magazine Luiza e, assim, a empresa conseguiu tomar as melhores decisões. Ou o modelo que utiliza um algoritmo de Machine Learning também da categoria Essemble que a Barbara Barbosa ajudou a desenvolver/treinar para acelerar e apoiar a decisão da Creditas de concessão ou não de empréstimo com garantia de imóvel a partir de dados do IBGE sobre a região em que a pessoa mora.
- Dataset: é um conjunto de dados que iremos passar para o modelo.
- DataFrame: é um tipo de dado estruturado da biblioteca Pandas, que tem um formato tabular, bem parecido uma tabela no banco de dados. Nele temos linhas, que são chamadas de “observação”, e colunas, chamadas variáveis.
- Atributos: as variáveis que vamos fornecer como entrada pro modelo.
E o que seria esse tal aprendizado de máquina?

O Aprendizado de Máquina é uma subárea da Inteligência Artificial, em que os algoritmos recebem a habilidade de aprender com os dados sem serem explicitamente programados. O aprendizado nada mais é do que encontrar padrões nos dados a partir de uma experiência, e com essa experiência o modelo vai conseguir prever, classificar ou agrupar novos dados de acordo com o objetivo dele. Uma vez que o algoritmo aprende, ele consegue realizar a mesma tarefa para novos conjuntos de dados.
Como iniciar um projeto com Aprendizado de Máquina?
Logo abaixo podemos ver o passo a passo (pipeline) que podemos tomar ao iniciar um projeto com aprendizado de máquina – muitas empresas utilizam esses passos em muitos projetos. Durante a Sprint PrograMaria, fizemos boa parte dessa jornada no Workshop Primeiros Passos com Machine Learning, com Fernanda Wanderley.
Cada passo possui uma série de atividades e análises a serem feitas, portanto além das etapas descritas na imagem acima, eu coloquei mais algumas que são super importantes de seguirmos:
- Entendimento do problema: Na IBM, a gente tem mais uma etapa antes da coleta de dados. Entendemos o problema, entrevistamos a pessoa cliente, identificamos qual dor queremos resolver e como poderemos ajudar a sanar ou a melhorar esse problema. Essa etapa é essencial para toda a pipeline que iremos executar, pois sem o entendimento do negócio, o modelo que faremos não vai ter utilidade para clientes finais. Após isso é realizado a coleta dos dados. Então, precisamos pensar o seguinte nesta etapa: Por qual caminho vou coletar meus dados? É via API? É via banco de dados?
- Entendimento dos dados: A partir de exploração, conseguimos entender qual o comportamento do dado, qual a distribuição, qual o tipo de dado (se ele é estruturado ou não estruturado), se há outliers (dados com valores atípicos) no datatset e por aí vai. Com essa exploração conseguimos entender qual o tipo de algoritmo podemos aplicar e também nesta etapa pode ser verificado se esses dados são o suficiente para chegar na solução do problema da pessoa cliente.
- Análise exploratória: assim como fazer um bolo, é preciso validar se há todos os ingredientes necessários antes de começar. Para saber mais sobre isso, clique aqui.
- Limpeza e pré-processamento: se no dataframe explorado tiver outliers eu os removo se necessário. Além disso, precisamos validar se tem dados faltantes, se houver, informar para a pessoa cliente que está faltando esses dados. Também é importante verificar se as colunas estão com o tipo certo, por exemplo: se o dataframe tem uma coluna de idade, faz sentido ela ser do tipo “float”? Para saber mais sobre pré-processamento, clique aqui.
- Treinar o modelo: Antes de passar os dados para o modelo, é recomendado ter pelo menos 2 datasets: um de teste e outro de treino. Eu recomendo dividir sua base em 20% para teste e 80% para treino. Os dados de treino deverão ser passados como input para o modelo realizar o treino. Essa etapa é bem importante pois assim além de treinar, é necessário saber o quanto seu modelo performa com dados que ele não conhece.
- Testar e avaliar os resultados gerados: O procedimento mais comum após treinar um modelo de Machine Learning é testá-lo para que saibamos se o modelo é capaz de generalizar bem para novos dados, onde é passado como input pro modelo os dados que ele nunca viu antes. As métricas são usadas para avaliar se o modelo está “bom” ou “ruim”, ou seja, se o modelo consegue se adaptar à novos dados. Para saber mais sobre métricas de validação para modelos de machine learning, clique aqui. Caso o resultado não seja bom, precisa ser reavaliado os parâmetros e verificar se os dados que você está usando realmente são necessários. E caso os resultados sejam bons, você pode entregar o modelo para a pessoa cliente.
Sempre que trabalhamos em um conjunto de dados para prever ou classificar um problema, alguns problemas comuns podem ocorrer, e é necessário ter atenção a eles: overfitting e underfitting.
O problema de overfitting ocorre quando seu modelo não generaliza bem para novos dados, ou seja, ele é bom somente nos dados de treino. Por exemplo: ele é têm uma acurácia muito alta em dados de treino, entretanto nos dados de teste ele não apresenta bons resultados. Portanto podemos dizer que o algoritmo memorizou ou se especializou nos dados de treinamento.
Já underfitting é o inverso do overfitting, eu tenho uma baixa taxa de acerto mesmo no subconjunto de treinamento, isso pode ocorrer por exemplo, quando os exemplos de treinamento disponíveis são pouco representativos ou o modelo usado é muito simples e não captura os padrões existentes nos dados.
Para saber mais sobre esses tipos de problemas e como evitá-los, o Data Hackers publicaram um artigo muito bom sobre isso, clique aqui.
Como as máquinas aprendem?
As máquinas podem aprender de 3 formas, dependendo de quais tipos de dados damos para o aprendizado e de qual problema queremos resolver:
- Aprendizado Supervisionado
- Aprendizado Não supervisionado
- Aprendizado por Reforço
Aprendizado supervisionado

No aprendizado supervisionado, nós temos a presença de uma pessoa “professora” ensinando para a máquina “Olha, o que tiver essas características é um gato, o que não tiver não é um gato”.
Seguindo essa linha de raciocínio, nos datasets nós temos a variável X (características ou variável independente) e a variável Y (alvo ou variável dependente), ou seja, a partir de uma nova entrada (X) eu consigo prever a minha saída (Y). Isso, porque quando eu inseri o meu dataset eu já tinha variáveis X e Y e foi daí que meu modelo tirou as previsões.
Por exemplo, o algoritmo vai classificar se um personagem é o Mario Bros ou não. Então, os nossos atributos X poderiam ser: bigode, chapéu vermelho e macacão azul, e nosso atributo Y vai ser a classe que o personagem pertence, por exemplo: 0 (se é o Mario) ou 1 (não é o Mario).

Em termos matemáticos, podemos dizer que a saída do modelo(Yˆ) é gerada através de uma função que recebe a variável independente.
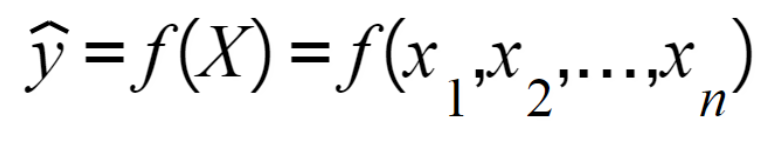
Então é passado para o modelo exemplos do personagem Mario, e exemplos que não são o personagem Mario, para que o modelo consiga entender o padrão. Logo depois deste treinamento, é realizado o teste, em que são utilizados exemplos que nunca foram vistos pelo modelo.
Um conjunto de testes é usado para avaliar se os relacionamentos descobertos são mantidos. Existem diversas métricas para determinar a qualidade de um modelo, para saber mais sobre As Métricas Mais Populares para Avaliar Modelos de Machine Learning.

Aprendizado não supervisionado

Neste tipo de aprendizado, não temos a presença de uma pessoa “professora”, portanto a máquina precisa aprender por si mesma os padrões e tendências existentes nos dados. Aqui, não temos a variável Y nos nosso dados de entrada.
Por exemplo, queremos explorar o dataset com alguns personagens da série Game of Thrones e com isso rodamos um algoritmo não supervisionado para entendê-los melhor. E o algoritmo nos retornou a saída abaixo com os clusters que ele formou, para quem não assistiu a série, o algoritmo acabou agrupando todos esses personagens que pertencem à mesma família, ou seja, podemos notar que no nosso dataset, temos 2 tipos de família e cada uma contém características próprias, mas que são comuns aos personagens que pertencem a ela.

Se você quer conhecer um pouco mais sobre esses aprendizados, eu fiz um artigo para a comunidade AI Girls sobre os tipos de aprendizado de máquina.
Aprendizado por Reforço
Neste aprendizado a máquina aprende através de feedbacks sobre os resultados que ela teve, e diante desse feedback a máquina ajusta seu comportamento de modo a sempre buscar o melhor resultado. Esse aprendizado é muito usado em games, drones e carros autônomos.
E quem mexe com aprendizado de máquina?
Muitas pessoas e profissionais podem aplicar o aprendizado de máquina! No mercado temos em especial 2 profissionais que mexem com essa área da Inteligência Artificial.
Cientista de dados
A área de ciência de dados é responsável por reunir e limpar grandes conjuntos de dados, criar modelos matemáticos e interpretar descobertas em soluções de negócios e, como diz uma grande amiga, cientistas de dados são as fadas que transformam os dados em conhecimento e valor. E quem não gostaria de ser uma fada?!
Engenharia de Machine learning
Cientistas de Dados e Engenheiros/as de Machine Learning trabalham juntos, pois os/as Engenheiros/as de Machine Learning geralmente fazem parte da equipe de Data Science (Ciência de Dados, em português) de uma empresa.
As responsabilidade de um/a engenheiro/a de Machine Learning pode variar conforme o projeto que for trabalhar. Normalmente essa pessoa fica responsável por desenvolver modelos de aprendizado de máquina, colaborar com engenheiras de dados para desenvolver e modelar pipelines de dados (desde a extração dos dados, exploração e desenvolvimento do modelo), e também é responsável por todo o ciclo de vida (pesquisa, projeto, experimentação, desenvolvimento, implantação, monitoramento e manutenção) do modelo e trazer código para produção.
Como iniciar estudos em Machine Learning?
Mesmo o mercado pedindo pessoas com experiências, não é impossível você entrar nele! Esses perfis profissionais requerem skills multidisciplinares, por exemplo, conhecer a área de negócios, programação, banco de dados e matemática. Portanto, muitas mulheres que estão em transição de carreira podem conseguir vagas nessa área.
Na minha empresa, conheço muitos e muitas cientistas de dados que se formaram em engenharia química, biólogos, relações internacionais etc.
Claro, tem algumas empresas que ainda pedem uma formação em tecnologia, o que vem mudando com tempo, e tem muitas outras que querem saber se você realmente sabe aplicar no seu problema de negócio e gerar valor para a empresa.

Linguagens de programação
Atualmente há 2 linguagens muito fortes nessa área: Python e R. Você não precisa conhecer as duas para entrar na área, conhecer bem uma delas já é um diferencial.
Tem cursos no Alura sobre essas linguagens, e promoções bem interessantes em alguns cursos na Udemy.
Além disso, tem a opção gratuita fornecida por algumas comunidades, entre elas as comunidades Pyladies e R-Ladies que fazem workshops ensinando respectivamente Python e R para mulheres.
Bibliotecas
Após aprender a linguagem de programação, é importante saber algumas bibliotecas que são muito utilizadas no mundo dos dados, para facilitar a manipulação e leitura dos dados. Recomendo estas bibliotecas em Python, nesta ordem:
Pandas: facilita a manipulação de dados. Tem um artigo bem legal do Minerando Dados sobre essa biblioteca, para acessar clique aqui.
Numpy: usada principalmente para realizar cálculos e manipulação de Arrays (para entender mais sobre Arrays, clique aqui).Para entender mais sobre essa biblioteca clique aqui.
Scikit Learn: é uma das bibliotecas mais utilizadas para processamento de dados e implementação de algoritmos de Machine Learning. O pessoal do Minerando Dados escreveu um artigo sobre essa biblioteca, que eu super recomendo a leitura, para acessar, clique aqui. Além disso, tem um curso bem bacana do cognitive class sobre isso.
Entender os dados
Antes mesmo de você sair querendo aplicar o aprendizado de máquina, é essencial entender e interpretar o comportamento dos dados, pois o seu algoritmo vai aprender com eles. Então você precisa saber se aqueles dados são suficientes para o seu modelo e se eles estão na estrutura necessária para o modelo. Além disso, é fundamental identificar os tipos de dados do dataset.
Tem uma trilha do Pizza de Dados sobre exploração visual dos dados, no alura tem curso com a linguagem R e python.
Algoritmos de aprendizado de máquina
Diagrama com os tipos de aprendizado de máquina e seus algoritmos
Além de saber os tipos de aprendizado de máquina é importante saber como aplicar cada algoritmo dependendo do problema. Por exemplo, para problemas de classificação, saber se um personagem é vilão ou herói, eu posso usar: Árvore de decisão, regressão logística, KNN, SVM, Naive Bayes entre outros.
Se o problema envolve regressão, ou seja, o Y é um número contínuo e é preciso olhar para o passado para prever o futuro, use algoritmos de regressão: Regressão linear, regressão não-linear, regressão linear Múltipla. Um exemplo para esse problema seria prever qual o melhor valor de um imóvel.
Agora, quando não há certeza da saída do modelo, pode-se usar algoritmos de agrupamento. Por exemplo: você quer entender melhor quais os perfis de clientes uma empresa tem. Você não sabe ao certo a quantidade de perfis de clientes que existem, então você pode usar por exemplo: DBSCAN, K-Means e K-Median.
Tem um curso bem legal do cognitive clas sobre aprendizado de máquina com python e com R , tem uma trilha do Pizza de Dados e do Coursera.
Matemática e Estatística

É, minha gente, precisamos saber matemática!
Aplicar um modelo de Machine Learning se tornou relativamente simples com o surgimento das bibliotecas, portanto o que vai te diferenciar de outros profissionais, será a skill em matemática para entender o que o algoritmo faz, por baixo dos panos. Afinal, os algoritmos basicamente vão trabalhar com funções matemáticas.
Matemática é importante no aprendizado de máquina, pois precisamos entender qual o melhor algoritmo, qual a melhor forma para avaliar o modelo.
A comunidade do Pizza de Dados fez uma trilha bem legal sobre matemática e estatística.
Conhecimentos em Github e git
Git é um sistema de controle de versão de arquivos. Através dele podemos desenvolver projetos nos quais diversas pessoas podem contribuir simultaneamente, editando, criando novos arquivos e permitindo que eles possam coexistir sem o risco de suas alterações serem sobrescritas.
Normalmente, você irá trabalhar com uma equipe e como em qualquer projeto de desenvolvimento, irá precisar armazenar seus códigos e juntar com os códigos do colega, e o Github faz esse papel.
Github uma plataforma de hospedagem de código-fonte com controle de versão usando o Git, onde podemos criar repositórios para armazenar nossos códigos.
Obs: Além disso ele pode servir como um ótimo portfólio!
Seja curiosa/o!
A curiosidade será sua grande aliada nessa jornada! É importante buscar sempre o porquê das coisas! A curiosidade fez o ser humano ter descobertas incríveis.
Antes e depois de construir nosso modelo, precisamos entender o porquê do comportamento dos dados, quais as melhores variáveis de entrada se dá para o modelo, e se ajustando o parâmetro do modelo, será que o resultado melhora?
Ademais, o modelo terá melhores resultados quanto mais curiosidade para fazer experimentos você tiver!
Tenha pensamento crítico!
Esse é uma dica superespecial. Ao mexer com Aprendizado de Máquina, você precisa ter criticidade com os resultados e com a exploração dos dados. É muito importante questionar “se o resultado não foi bom, como melhorar? Será que se eu adicionar mais dados o resultado melhora? Será que tem outro modelo que eu posso utilizar?”,”Meu modelo apresenta problemas no aprendizado?”, “Se eu usar X, Y como entrada será que melhora o resultado?”
Tenha lógica!
Estamos tentando transformar um problema do mundo real em uma solução computacional, portanto, é crucial termos uma boa lógica, pois você irá passar grande parte do seu tempo escrevendo linhas de códigos.
Tem um artigo no Medium bem interessante, com uma trilha de lógica de programação.
Seja comunicativa/o!
Para descobrir mais sobre o problema que queremos resolver, precisamos conversar com a pessoa cliente e com o time com que iremos trabalhar. Portanto, a comunicação é uma das habilidades chave para essas pessoas! Lembre-se de fazer perguntas objetivas e que irão te ajudar.
Participe de comunidades e eventos que envolve a área de dados
Por fim, existem diversas comunidades que realizam eventos ou meetups sobre Aprendizado de Máquina:
- AI Girls
- Escola Livre de IA
- Woman in Data Science São Paulo
- Woman in Machine learning & Data Science(WIMLDS)
- AI Brasil
- DevAIWoman (Iniciativa da comunidade Developers BR)
Participar de comunidades faz você ficar mais antenada nas tecnologias da área, além de conhecer pessoas sensacionais e fazer networking!
Inteligência artificial é a área do futuro, entretanto somente 22% das pessoas profissionais de Inteligência Artificial são mulheres, comparado com 78% de profissionais homens. Esses são dados do Global Gender Report em 2018.
Conseguimos realizar grandes coisas em diversas áreas com essas ferramentas! Vamos ocupar também a área de Inteligência Artificial e Machine Learning!
Para saber mais: leia o artigo da Mikaeri Ohana sobre Como iniciar na carreira de ciência de dados.
Oiii pessoal meu nome é Laura tenho 20 anos e sou estagiária em análise de dados no IBM. Sou cofundadora e organizadora da comunidade AI Girls e atualmente sou organizadora da comunidade DevAIWoman. Sou apaixonada por IA e ciência de dados, acredito que ambos podem causar uma transformação incrível na sociedade.