
Com o machine learning (aprendizado de máquina), o time melhora resultados de varejistas e avalia crédito das pessoas donas de lojas que utilizam a plataforma; saiba mais
O Olist é uma startup que nasceu em Curitiba e que possui como missão empoderar o comércio. Um dos seus produtos é uma plataforma que permite que pessoas donas de lojas vendam seus produtos nos sites de grandes redes varejistas, oferecendo também suporte na gestão, logística e atendimento ao consumidor final e outros serviços.
Ao longo de 2021, foi implementado um projeto de aprendizado de máquina (machine learning) que prevê cancelamentos de pedidos. Esses cancelamentos podem acontecer por vários motivos: arrependimento do consumidor final, erros operacionais, falta de estoque, entre outros.
Para entender melhor como o projeto de machine learning funciona, observe a imagem abaixo, de um dos anúncios do Olist, retirada do site do Magazine Luiza.
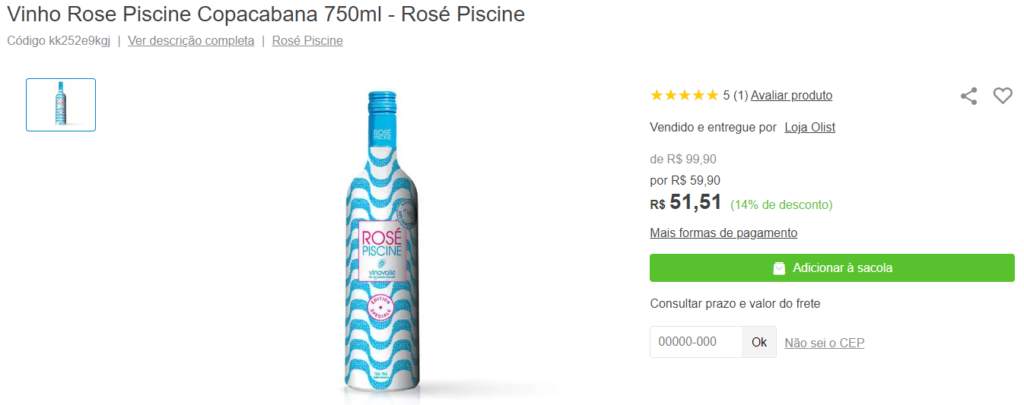
O que indica o nosso anúncio é a frase “Vendido e entregue por Loja Olist”, logo abaixo das 5 estrelas. Neste caso, quando recebemos uma venda desse produto, repassamos o pedido para a nossa loja parceira, que emite a nota fiscal e a envia ao transportador indicado por nós.
Após o envio desse produto à pessoa consumidora final, a loja parceira receberá o valor dessa venda em datas pré-definidas. Para contemplar quem deseja adiantar o recebimento desses valores, nasceu o saque flexível. Porém, quando o pedido é cancelado, o valor deve ser devolvido à pessoa que comprou o produto. Como esses cancelamentos são um risco ao Olist, foi necessário criar esse modelo, para evitar prejuízos com essa modalidade de crédito.
Modelo de cancelamento de pedidos
Os primeiros passos desse projeto se deram com o início de uma análise exploratória dos dados (EDA). A ideia era procurar por insights e relações entre as variáveis, e formular hipóteses para nortear o modelo que seria usado futuramente. A princípio, observamos variáveis como a própria taxa de cancelamento, a taxa de entrega e o envio dentro do prazo, a flutuação de preços, o preço de frete etc. Foram construídas variáveis com 3 janelas de tempo – 30, 60 e 90 dias –, justamente para descobrir qual seria aquela mais apropriada para o modelo.
A previsão de cancelamento de pedidos é fornecida de duas formas: uma é em forma de número inteiro positivo e, a outra, o seu intervalo de confiança. Foram usados 2 modelos diferentes, chamados Light Gradient Boosting Machine (LightGBM) e Natural Gradient Boosting (NG boosting).
O LightGBM é uma biblioteca open source que nos fornece uma implementação eficiente e eficaz do algoritmo de gradient boosting, uma técnica amplamente utilizada para problemas relacionados à regressão e classificação. Neste caso, a previsão de cancelamentos de pedidos é um problema relacionado à regressão e o lightGBM nos fornece a quantidade de pedidos que podem ser cancelados.
O modelo de NG boosting nos fornece esse intervalo para a quantidade de cancelamentos, uma estimativa da incerteza para cada previsão por meio da previsão probabilística, em que o modelo produz uma distribuição de probabilidade completa em todo o espaço de resultados.
Estimar a incerteza nas previsões de um modelo de machine learning é um ponto a ser discutido na implementação desses projetos. Mesmo o modelo trazendo previsões precisas, também é muito importante uma estimativa correta da incerteza de cada previsão, por isso o uso do NG boosting. Quando as previsões do modelo fazem parte de um fluxo de tomada de decisão, as estimativas de incerteza preditiva são importantes para determinar alternativas de fallback manual ou inspeção e intervenção humana.
Modelo de risco de crédito
No início, muitos desafios foram elencados como:
– Qual o perfil operacional da pessoa lojista que solicitasse esse serviço de crédito;
– Qual seria o melhor modelo para fornecer essa previsão de cancelamento;
– Dado essa previsão de cancelamento, qual seria o percentual adiantado para essa pessoa.
Com o retorno do modelo de previsão de cancelamentos de pedidos, foi possível, junto com a área de negócios, estabelecer as regras de perfil de lojista que tem acesso ao saque flexível.
Durante o projeto, foi fundamental a participação da área de negócios para melhorar o modelo, fornecendo regras de negócios e insights durante todo o processo e, depois, validando os resultados.
Autoras Simone Sales é cientista de dados no Olist, formada em Ciências Econômicas pela Universidade Federal do Paraná (UFPR), com especialização em inteligência artificial e aprendizado de máquina. Atua na área de ciência de dados há 3 anos, trabalhando principalmente com dados de varejo e segmentação de clientes. Verônica Pacheco é engenheira de dados no Olist. Atua há 7 anos na setor de tecnologia e sempre foi apaixonada pela área de dados. Miriam Oliveira dos Santos é cientista de dados no Olist, com aproximadamente 22 anos de experiência na área de Tecnologia de Informação. Tem formação acadêmica em Computação, com graduação, mestrado e doutorado na área. Acredita no poder transformador que a Educação pode proporcionar tendo vivenciado esta experiência em sua própria trajetória de vida. Revisora Stephanie Kim Abe é jornalista, formada pela Escola de Comunicações e Artes da Universidade de São Paulo (ECA-USP). Trabalha na área de Educação e no terceiro setor. Esteve nos primórdios da Programaria, mas testou as águas da programação e achou que não era a sua praia. Mas isso foi antes do curso Eu Programo…
Este conteúdo faz parte da PrograMaria Sprint Área de dados.
O que você achou deste conteúdo? Responda nosso feedback:
Sigo aprendendo muito com vocês.