
Você sabe como funciona um projeto em dados? Nesse artigo, vamos passar pelos principais pontos do ciclo de vida de um projeto de dados, desde o entendimento de negócio até a fase de deploy e monitoramento dos modelos
Você já parou para pensar em quais são as etapas que envolvem o desenvolvimento de um projeto de dados? Muitas pessoas acreditam que basta aprender as implementações de alguns modelos de aprendizado de máquina (machine learning, em inglês) e aplicar seus dados neles que o seu projeto está pronto — mas isso está longe de ser verdade!
O fato é que a parte do treinamento que envolve aprendizado de máquina é apenas um pedaço do projeto em si: normalmente apenas 10% de todo o trabalho que a pessoa cientista de dados desenvolve. Um projeto completo de dados é um ciclo de vida composto por várias etapas que podem ser retomadas mais de uma vez para garantir a obtenção de um modelo de qualidade.
A seguir, explico cada uma das etapas do ciclo de vida de um projeto de dados, com base na imagem abaixo.
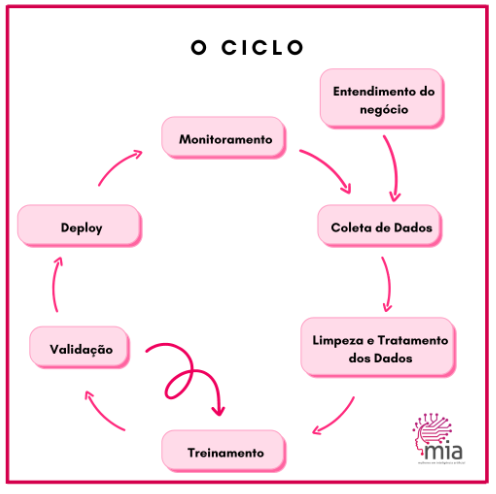
Para facilitar o entendimento, também usarei dois cases diferentes para explicar o que é preciso fazer em cada uma dessas etapas nos dois casos:
Projeto A: Modelo de predição de cancelamento de clientes.
Projeto B: Modelo de classificação de pneumonia em análise de raio-x.
Entendimento do negócio
Essa é uma das partes fundamentais do projeto. Afinal, para criar um modelo, é necessário entender o seu objetivo e um pouco do contexto no qual nos encontramos.
No Projeto A, precisamos conversar com a área de negócios para entender, por exemplo:
– Qual o fluxo de vida do cliente dentro do negócio;
– O que, na visão deles, pode impactar esse cancelamento;
– Se existem variáveis (features, em inglês) sazonais — por exemplo, um período de reajuste de preço — ou regionais (como bairros em que existe um melhor ou pior atendimento).
Além disso, precisamos entender quando e como esse modelo poderia ser usado. Se a predição for feita com um mês de antecedência é suficiente? As ações tomadas estariam de acordo?
 No Projeto B, apesar da variável em questão ser mais simples — imagens de exames de raio-x — precisamos entender como essa alteração é apresentada no exame:
No Projeto B, apesar da variável em questão ser mais simples — imagens de exames de raio-x — precisamos entender como essa alteração é apresentada no exame:
– Existe algum formato ou aspecto específico?
– Pode aparecer em qualquer região do pulmão?
A partir dessas perguntas, pensar em algoritmos de processamento de imagens que possam auxiliar se usados antes do treino. Da mesma forma, precisamos entender como que a pessoa médica pode usar esse modelo. Só a apresentação da probabilidade é suficiente? Uma marcação no exame, como um GradCAM, pode ajudar a entender melhor o resultado?
Tendo esses entendimentos prévios, podemos partir para a coleta de dados para começar o nosso desenvolvimento. Caso haja dúvidas durante a análise, é preciso voltar a conversar com a equipe de negócios.
Coleta de dados
Reunir os dados para criar a modelagem pode ser simples, bastando executar uma query SQL em uma base de dados. Mas, dependendo do negócio e da necessidade, pode ser uma tarefa bastante trabalhosa. Pode ser necessário capturar dados de fontes diversas e, em alguns casos, fazer raspagem de dados (web scraping), ou seja, ter que criar um script que faça download de dados da internet de maneira automatizada, como por exemplo, baixar tweets para criar um modelo que analise fake news.
Então, tendo entendido quais as principais variáveis que precisamos para a criação do modelo, é hora de conversar com a equipe responsável pelos dados, que pode ser a equipe de Engenharia de Dados ou a própria equipe de Produtos, dependendo da estruturação da empresa.
 No caso do Projeto A, essa conversa serve para entender onde estão os dados, se há um banco com as atualizações temporais dos clientes e se todas as variáveis que precisamos estão disponíveis. A partir daí, estabelecemos um período para a coleta, desenhamos a query e realizamos a extração dos dados.
No caso do Projeto A, essa conversa serve para entender onde estão os dados, se há um banco com as atualizações temporais dos clientes e se todas as variáveis que precisamos estão disponíveis. A partir daí, estabelecemos um período para a coleta, desenhamos a query e realizamos a extração dos dados.
Um ponto importante a ser lembrado é que as variáveis coletadas para o treino serão as mesmas usadas para a predição, portanto não adianta adicionar dados que só estão disponíveis uma vez.
Já no Projeto B, precisamos entender se a quantidade de exames que temos com e sem pneumonia é suficiente para treinamento ou se será necessário, por exemplo, baixar dados de datasets públicos disponíveis na internet.
Limpeza e Processamento de Dados
Nesta etapa, precisamos fazer a limpeza de dados inválidos, corrigindo valores faltantes quando necessário, removendo outliers, selecionando boas variáveis e criando outras através de combinação de valores. Não à toa, essa é a tarefa mais trabalhosa, demorada e fundamental para garantir o bom funcionamento de um projeto de dados.
No nosso Projeto A, precisaríamos, dentre outras ações,:
– Tratar dados de localização (como latitude e longitude) e de faltantes (como cliente sem idade cadastrada);
– Criar novas variáveis que ajudem a definir o perfil do cliente (tais como quantidade de compras no últimos mês ou trimestre);
– Dependendo da quantidade de variáveis e de amostra que tivermos, usar algum algoritmo de seleção de variáveis para evitar o problema da maldição da dimensionalidade.
No Projeto B, podemos aplicar algoritmos para melhorar a qualidade da imagem, como equalização do histograma, ou fazer segmentação da imagem de acordo com o que foi determinado pelo médico.
É nessa etapa também que avaliamos o balanceamento do nosso dataset, podendo aplicar técnicas de balanceamento quando necessário, e fazemos a nossa análise descritiva, entendendo como as variáveis estão se comportando mesmo antes do treinamento e se as hipóteses da área de negócios fazem sentido.
Outra coisa muito importante nessa etapa é a remoção ou o balanceamento de variáveis que possam causar algum viés no nosso modelo. Por exemplo, se estamos criando um modelo que vai auxiliar empresas a fazerem contratações, ter variáveis como sexo e etnia pode causar um grande problema de viés. Assim, o ideal é que essas variáveis sejam balanceadas entre as classes no treino — como colocando no meu dataset a mesma quantidade de homens contratados quanto de mulheres, assim como de pessoas desclassificadas. Quando isso não for possível com os dados existentes, vale usar métodos de aumento de dados (Data Augment, em inglês) específicos para isso.
Treinamento
Chegou a etapa do ciclo que leva toda a fama! Aqui, já com os dados organizados, limpos e tratados, os separamos em três grupos: treino, teste e validação.
O treino e a validação são usados durante o treinamento, sendo o treino para treinar o algoritmo em si e a validação para testar os parâmetros do algoritmo. Devemos guardar os dados que ficaram em teste para a etapa seguinte. Existem outras formas de fazer essa separação entre treino e teste, como, por exemplo, com validação cruzada, separando os dados em vários folds.
Tendo feito essa última organização, é hora de você brilhar com os seus conhecimentos de aprendizado da máquina. O ideal é escolher algoritmos para testes que se encaixem com o seu problema, começando com os mais simples e, somente caso necessário, passando para algoritmos mais complexos.
 No nosso Projeto A, em que buscamos um modelo de predição de cancelamento de clientes, provavelmente uma regressão logística ou até uma árvore de decisão, dependendo da complexidade e quantidade de variáveis, pode resolver o problema. Caso não, podemos tentar algoritmos de Boosting como Random Forest ou Light Gradient Boosting. Ou ainda fazer ensembles com os próprios algoritmos mais simples, por exemplo, combinar as probabilidades da regressão logística com as da árvore de decisão. Se nada disso resolver, tentamos passar para algoritmos ainda mais robustos como deep learning.
No nosso Projeto A, em que buscamos um modelo de predição de cancelamento de clientes, provavelmente uma regressão logística ou até uma árvore de decisão, dependendo da complexidade e quantidade de variáveis, pode resolver o problema. Caso não, podemos tentar algoritmos de Boosting como Random Forest ou Light Gradient Boosting. Ou ainda fazer ensembles com os próprios algoritmos mais simples, por exemplo, combinar as probabilidades da regressão logística com as da árvore de decisão. Se nada disso resolver, tentamos passar para algoritmos ainda mais robustos como deep learning.
Porém, os algoritmos de deep learning costumam performar melhor do que os outros citados apenas em casos em que a massa de dados é muito grande ou para dados não-estruturados. Para classificação de imagens — como é o caso do nosso Projeto B, por exemplo —, algoritmos de deep learning costumam ter uma performance muito melhor do que os algoritmos de processamento de imagens clássicos.
Isso não exclui, porém, a possibilidade de você combinar as duas abordagens, adicionando variáveis extraídas com processamento de imagens junto com a imagem na entrada do algoritmo de deep learning.
Independentemente do algoritmo que escolher, a parametrização é muito importante. Apesar de para alguns algoritmos os parâmetros padrões funcionarem muito bem na maioria dos casos, às vezes a troca de algum parâmetro pode resultar em uma melhora incrível de resultados. Por isso, não se esqueça de testar! Isso é particularmente verdade para alguns algoritmos clássicos como SVM e também para a própria deep learning.
Validação
Agora, com o seu modelo treinado, está na hora de avaliar os resultados!
É importante ter os dados separados para teste para garantir que o seu modelo não está com overfitting, ou seja, que ele não tenha se super ajustado aos dados de treino. Por isso, testamos nos dados de teste e calculamos as métricas necessárias de acordo com o nosso problema.
Se for um problema de classificação, como é o caso dos nossos dois projetos, as métricas normalmente são:
– curva ROC
– área sob a curva ROC (AUC – do inglês “area under the curve”)
– acurácia
– precisão
– sensibilidade (ou recall).
É importante notar qual métrica é mais relevante de acordo com o seu problema. Se estou tratando de uma classificação de um problema de saúde, a sensibilidade é mais importante, pois é melhor capturar a maior quantidade de doentes corretamente, mesmo que algumas pessoas saudáveis sejam incorretamente classificadas como doentes. Porém, eu também não posso ter uma precisão muito ruim, para que pessoas saudáveis não passem pelo stress de acharem que estão doentes. Por isso, é preciso definir um bom limiar (threshold) de probabilidade que dê o equilíbrio que estamos procurando.
Por exemplo, pode ser que para o Projeto A, com uma porcentagem acima de 40% de chance de cancelamento, eu consiga capturar 90% dos clientes que tem chance de cancelar (sensibilidade de 90%), podendo assim tomar ações que evitem que isso aconteça, mesmo que, de todas as pessoas que eu fale que irão cancelar, apenas 75% realmente o fizessem (precisão de 75%).
Ainda, dependendo da sua aplicação, é importante procurar datasets externos para teste. Por exemplo, no caso do Projeto B, um algoritmo que funciona bem para um hospital não significa que funcionará bem em outro, pois há variações na forma de geração da imagem. Para testar essa variável, é importante obter imagens de outras fontes e ver como o algoritmo performa com elas.
Dependendo dos resultados da validação, pode ser necessário voltar para o treinamento ou até mesmo para a etapa de processamento de dados para modificar as variáveis e evitar alguns erros percebidos. Às vezes, pode acontecer de retornar para a etapa de coleta de dados, caso seja percebida a necessidade de mais dados ou de outras informações.
A interpretabilidade do algoritmo pode ser uma etapa realizada para avaliar melhor a parte de variáveis, permitindo, através de algumas técnicas e frameworks, que possamos desvendar a caixa preta e entender porque o algoritmo deu uma determinada resposta.
Não existe modelo com métricas em 100%! Se isso ocorrer, algo está errado: ou o seu modelo está hiper desbalanceado, ou você adicionou alguma variável no treino que está dando direto a resposta da classificação, ou você está validando com dados de treino. Enfim, é importante revisar o processo com calma para garantir que não ocorreram erros.
Deploy
O deploy consiste em deixar o seu modelo disponível para que outros serviços possam acessá-lo. Dessa forma, ele poderá de fato ser utilizado dentro do ecossistema da empresa ou diretamente pelos clientes do seu serviço.
O deploy normalmente consiste na criação de uma API com um endpoint específico para a predição (veja o workshop que preparamos 😉), mas também pode ser feito de algumas outras formas, como uma comunicação por mensageria ou até mesmo uma predição por batch em script.
Monitoramento
Avaliar o seu modelo enquanto em produção é uma etapa ainda pouco valorizada. Os dados não são fixos, portanto uma mudança de comportamento pode alterar todos os resultados. Por isso, é importante monitorar o andamento e entender quando é hora de capturar novos dados e retreinar o seu modelo. Independentemente do projeto, essa etapa consiste em capturar os dados e as predições do modelo que estão em produção, e fazer as mesmas análises de validação do modelo. Se percebemos que o modelo está caindo em relação às métricas definidas — por exemplo, acurácia — e está muito pior do que com os dados utilizados na validação, é hora de pegar mais dados e retreinar o modelo.
Autora Jéssica dos Santos de Oliveira é head de dados na NeuralMed, onde atua utilizando deep learning para auxiliar no diagnóstico e melhorar os sistemas de saúde em geral. Já trabalhou como cientista de dados em empresas do mercado financeiro e tem mestrado em Sistema de Informação, com linha de pesquisa em Inteligência de Sistemas. Seu projeto foi usar modelos de atenção visual baseados em reconhecimento de padrões para identificar autismo. Também participa de projetos que incentivam mulheres na área, sendo embaixadora do Women in Data Science (WiDS) São Paulo desde 2019, e cofundadora do Mulheres em IA (MIA), comunidade criada em 2020 durante a pandemia para abraçar e incentivar as mulheres que trabalham com dados. Revisora Stephanie Kim Abe é jornalista, formada pela Escola de Comunicações e Artes da Universidade de São Paulo (ECA-USP). Trabalha na área de Educação e no terceiro setor. Esteve nos primórdios da Programaria, mas testou as águas da programação e achou que não era a sua praia. Mas isso foi antes do curso Eu Programo…
Este conteúdo faz parte da PrograMaria Sprint Área de dados.
O que você achou deste conteúdo? Responda nosso feedback:
muito interessante. estou começando nessa area, e toda informação é muito bem vinda!!