
Entenda o conceito desses elementos essenciais na arquitetura de dados para definir a melhor opção para sua necessidade
Um dos maiores desafios de times de engenharia de dados é fornecer dados de forma rápida, segura e escalável para responder à expectativa de crescimento da empresa. Para isso, é necessário entender os elementos de uma plataforma de dados para escolher a melhor opção para cada situação. Data lake e data warehouse são elementos essenciais na arquitetura de dados moderna, mas suas definições e aplicações ainda podem ser confusas, principalmente quando o termo lakehouse entra na jogada. O objetivo deste artigo é lançar uma luz nas diferentes aplicações de cada um.
Uma breve história da arquitetura de dados
O conceito de data warehouse surgiu ainda nos anos 60, mas só foi de fato implementado pela primeira vez nos anos 80, pela Teradata. Em termos gerais, data warehouse pode ser considerado um repositório central de dados otimizado para demandas analíticas, unindo diferentes fontes e sistemas, e podendo ser acessado por ferramentas de Business Intelligence (BI) e clientes SQL. A partir dos anos 90, o data warehouse predominou como um dos mais importantes elementos da arquitetura de dados das empresas, em um primeiro momento com soluções on-premise (infraestrutura gerenciada pela própria empresa) e depois tornando-se disponível na nuvem.
A forma padrão de trabalhar com dados nesse contexto era o ETL (do inglês extract, transform e load – em português extração, transformação e carga), pois, por questões de custo e para otimizar a leitura, os dados precisavam ser transformados e agregados antes de serem carregados. No entanto, esse modelo apresenta limitações quando o volume começa a crescer e passa a envolver dados não estruturados. Assim, o ELT (onde a carga para o armazenamento vem antes da transformação) se tornou mais comum, principalmente com o advento do datalake.
O termo data lake surgiu mais recentemente, sendo usado pela primeira vez em 2011, e se popularizou com ascensão do armazenamento e da computação na nuvem, passando a ser adotado pelas empresas por ser mais escalável devido ao desacoplamento entre computação e armazenamento e a possibilidade de armazenar dados não estruturados.
Data lake pode ser definido como um repositório centralizado para armazenamento de dados estruturados (tabelas de bancos de dados relacionais, planilhas do Excel) e não estruturados (imagens, dados de redes sociais) em qualquer escala, onde diversas fontes podem ser ingeridas e com diferentes periodicidades. Nele, não é necessário definir de antemão o esquema (ou seja, a estrutura) dos dados ingeridos, pois nesse caso temos um comportamento chamado esquema na leitura (schema on-read, em inglês) o que contribui para se ter mais flexibilidade e velocidade na captura dos dados e na natureza dos dados em si.
Evidentemente, o data lake precisa de mecanismos de governança de dados: catálogo, metadados, testes de qualidade e segurança; sem isso é muito provável que acabemos gerando um pântano de dados, muito conhecido pelo termo em inglês data swamp, onde ninguém sabe de onde veio, o que significa e qual o valor gerado por aquele dado.
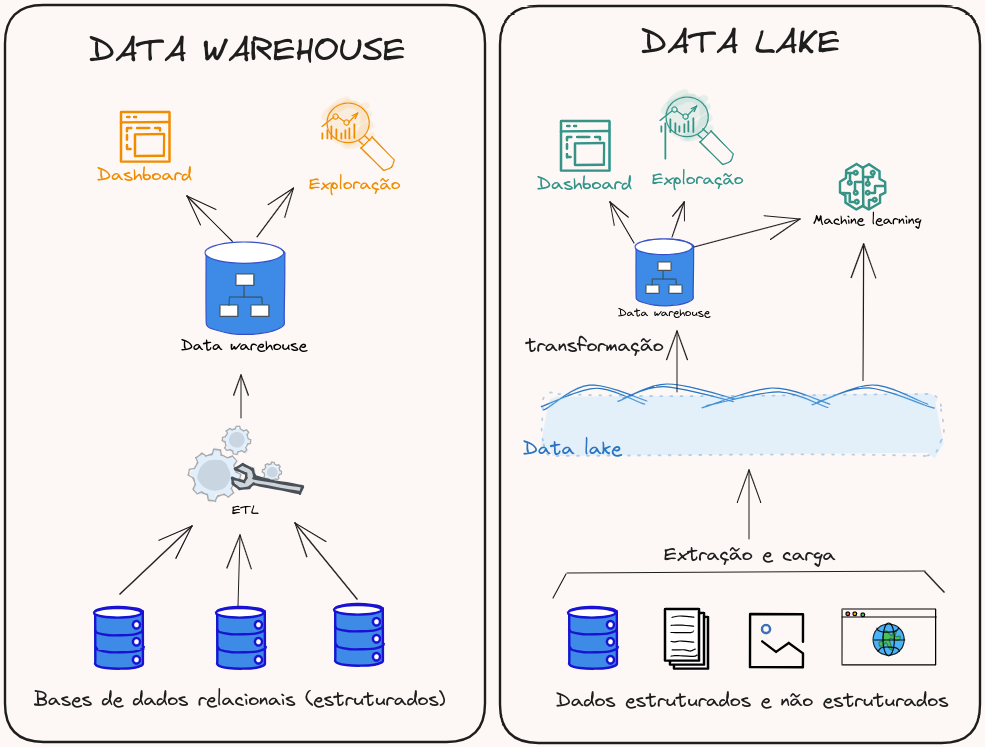 Figura 1: Comparação entre data warehouse e data lake (Autoria própria)
Figura 1: Comparação entre data warehouse e data lake (Autoria própria)
Quando utilizar um data lake e um data warehouse?
Após esse breve histórico, você deve estar se perguntando: “Então quer dizer que o data lake é a evolução do data warehouse?”. E a resposta é: não, dependendo do uso, você pode ter um ou outro (ou ambos!).
O data lake é mais indicado quando você está buscando mais velocidade na ingestão, precisa armazenar dados não estruturados ou não quer definir o esquema de antemão, pois ainda não sabe quais perguntas vai precisar responder. Atualmente, as ferramentas mais comuns para armazenamento de dados de um data lake são dos provedores de nuvem pública, por exemplo, a AWS tem o S3, a Google Cloud tem o Cloud Storage e a Azure tem o Azure Data Lake.
Já o data warehouse pode ser mais vantajoso quando você precisa executar consultas SQL de forma rápida, com o esquema dos dados já predefinido e com contextos específicos. É geralmente usado como fonte de relatórios, com os dados já limpos e transformados. Ferramentas populares são o Redshift, BigQuery, Azure Synapse Analytics e Snowflake.
Vale destacar que data warehouses também são frequentemente construídos em cima de um data lake. Uma arquitetura super comum da AWS é utilizar o S3 como data lake e o Redshift como data warehouse, por exemplo.
Lakehouse: a arquitetura de dados do futuro?
O surgimento do data lake foi muito importante para as empresas. No entanto, ele ainda não fornece alguns recursos importantes, como consistência e isolamento entre leitura e escrita e não forçar a aplicação de qualidade de dados. Uma alternativa seria manter um data lake e um data warehouse (como a arquitetura exemplificada na figura 1 à direita), porém, ter que dar manutenção para as duas ferramentas pode ser inviável para alguns times e, ainda assim, ao realizarmos escrita e leitura concorrentemente no data lake poderíamos ter inconsistências.
Assim, uma nova proposta de arquitetura surgiu, combinando as melhores características do data lake e do data Warehouse, denominada lakehouse. O lakehouse permite guardar dados em um armazenamento de objetos como um data lake e garante transações ACID (com Atomicidade, Consistência, Isolamento e Durabilidade) por meio da aplicação de formatos de tabela open-source como Delta lake, Apache Iceberg e Apache Hudi, que possibilitam que os dados sejam inseridos, atualizados e deletados sem risco de serem corrompidos.
Por ser construído em cima do data lake, o lakehouse nos permite interagir com todos os dados armazenados ao mesmo tempo que provê uma camada de governança com metadados que transformam a parte não estruturada (arquivos) em tabelas e catálogos de dados também open-source, assim diferentes aplicações, desde Data Science e Machine Learning até ferramentas de BI, podem acessar a mesma interface para interagir com dados.
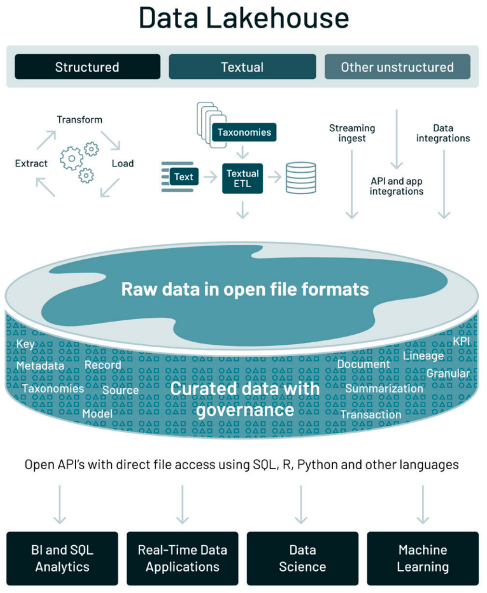
Figura 2: Arquitetura lanekouse (Databricks)
A arquitetura lakehouse é open-source e é totalmente viável que você construa o seu próprio lakehouse, usando os formatos de arquivos abertos. Existem, porém, empresas que vendem plataformas prontas para uso, como, por exemplo, Databricks, Dremio e Starburst, que são boas opções para times enxutos e/ou sem tanta maturidade técnica.
Como vimos, as opções são variadas e tudo depende do seu caso de uso. Apesar do lakehouse estar evoluindo rapidamente, ainda existem situações nas quais apenas o data lake ou o data warehouse (ou a combinação dos dois) basta.
Espero que esse artigo seja útil para suas próximas decisões arquiteturais. Sinta-se à vontade para se aprofundar nas referências.
Para saber mais/ Referências:
- O que é um data lake? Disponível em: https://cloud.google.com/learn/what-is-a-data-lake
- O que é um data lake? Disponível em: https://aws.amazon.com/pt/big-data/datalakes-and-analytics/what-is-a-data-lake/
- O que é um data lake? Disponível em: https://azure.microsoft.com/pt-br/resources/cloud-computing-dictionary/what-is-a-data-lake/
- A Brief History of Data Lakes. Disponível em: https://www.dataversity.net/brief-history-data-lakes/
- Lakes? Warehouses? Lakehouses? A short history of Data Architecture. Disponível em: https://medium.com/quantumblack/lakes-warehouses-lakehouses-a-short-history-of-data-architecture-bc942b0ed463
- The Evolution of Data Lake Architectures. Disponível em: https://tdwi.org/articles/2020/05/29/arch-all-evolution-of-data-lake-architectures.aspx
- Snowflake, Redshift, BigQuery and Others: Cloud Data Warehouse Tools Compared.Disponível em:
https://altexsoft.medium.com/snowflake-redshift-bigquery-and-others-cloud-data-warehouse-tools-compared-fc520d13b5d3 - Frequently Asked Questions About the Data Lakehouse. Disponível em: https://www.databricks.com/blog/2021/08/30/frequently-asked-questions-about-the-data-lakehouse.html
- What is a Lanehouse? Disponível em: https://www.databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
Autora
Larissa Mendes Hermógenes Rocha
Engenheira de dados na Gupy, atualmente trabalha com foco em engenharia analítica. Com formação em engenharia mecânica, migrou para a área de dados há quase 3 anos e se encontrou. É membra da comunidade Data Girls e ama ajudar a impulsionar mulheres na tecnologia. Revisora
Luciana Fleury, jornalista
Este conteúdo faz parte da PrograMaria Sprint Dados: ampliando fronteiras
Boa tarde! Informações muito relevantes que agregar meus conhecimento.
Gratidão